Definition
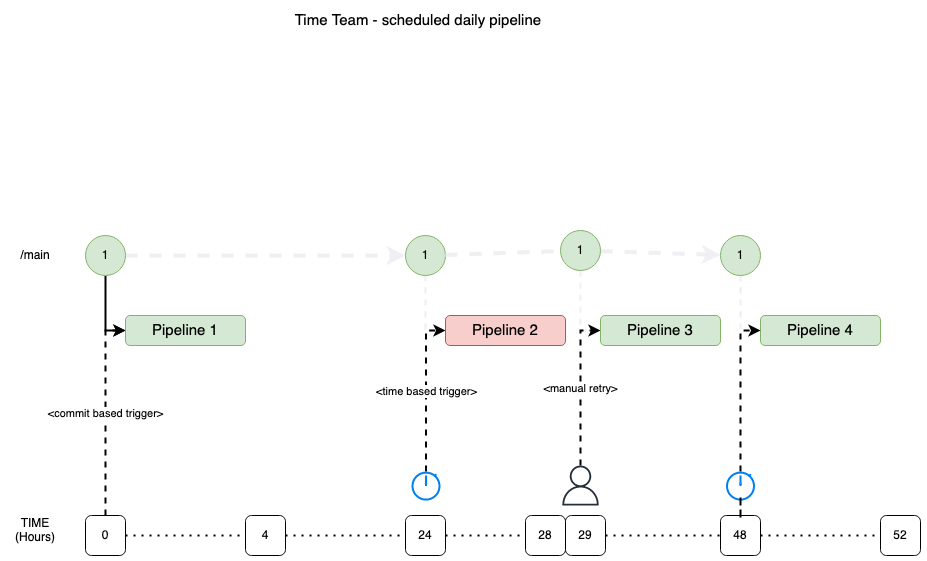
Deployment Frequency is the DORA corollary to Batch Size in Lean Theory. More specifically, deployment frequency measures the reciprocal of batch size - increasing deployment frequency reduces batch size.
Batch size measures inventory - work in process, a form of waste.
A closer definition for batch size would be “pending change sets”:
- Pending, to designate it is waiting to be deployed to production
- Change set, a deployable unit since individual commits may be too fine grained to be considered deployable.
However, identification and measurement of the above definition is more complex to track, and ultimately DORA’s definition of deployment frequency is a suitable corollary:
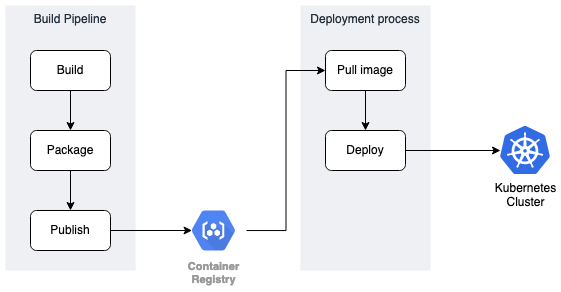
- If a team is practising Continuous Delivery, then there should be a close to 1-1 correlation between commit and change-set.
- If a team is deploying multiple times per day, then by definition it demonstrates the team are delivering in small batches.
Classification
WayFinder calculates a classification tag for deployment frequency to allow you to compare your performance with wider industry performance.
Classification tags are based on industry standards and DORA findings.
| elite | high | medium | low | |
|---|---|---|---|---|
| deployment Frequency | On demand (multiple deploys per day) | Between once per day and once per week | Between once per week and once per month | Between once per month and once every six months |